
Cloud computing has revolutionized the way we think about computing resources and storage capacity. With the ability to access virtually unlimited resources on demand, it can feel like we have an almost infinite capacity at our fingertips. Without enough resources, system performance will degrade and grind to a stall. Capacity planning is a critical challenge in running systems and we don’t always learn how to be effective at it. capacity planning can be time-consuming and requires careful analysis and consideration of various factors such as cost, scalability, and reliability.
Let’s go through the process of capacity planning with a toy example. Let’s start with the following assumptions:
- the system is processing
1,000 QPS(queries per second) on average. - this is processed with a pool of servers each of which can process
100 QPS. - each server needs 1 core and 4 GiB of RAM.
How much compute should we provision for this system?
Attempt #1
We need 10 servers to service the 1,000 QPS. That means 10 cores and 40 GiB of
RAM. Easy peasy!
Hmm… the customers are complaining about performance. They are hard to please, aren’t they? Let’s look deeper.
Attempt #2
Crikey! The 1,000 QPS was the average load. Duh. Demand varies across the
day and the week. We should be capacity planning for peak load. Turns out
that the peak load is 2,000 QPS. That means we need twice as many servers!
Expensive, but at least they stop whining now.
Well not quite. This ungrateful lot is still unhappy.
Attempt #3
Of course. The queries aren’t equal cost - some queries are more expensive and take more compute time to respond to. That means we are never quite going to be able to distribute them perfectly and run them at a 100% utilization rate, are we?
Say the load is Poisson distributed and we want to maintain 3 9s (i.e., ensure
99.9% of queries comply). Ideally, our throughput should provide a latency of
1/100=0.01s or 10ms. Our customers expect an SLO of < 20ms for 99.9% of
requests. Let’s start by checking what it would be at the 99.9th
percentile with the current provisioning.
import ciw
import numpy as np
import math
def get_lognormal_vars(mean, sd):
var = math.log((sd * sd)/(mean * mean)+1)
mu = math.log(mean) - var/2
return mu, math.sqrt(var)
def get_service_time(qps, utilization_ratio, throughput, sigma):
server_count = math.ceil(qps / throughput * utilization_ratio)
print(server_count)
N = ciw.create_network(
arrival_distributions=[ciw.dists.Exponential(rate=qps)],
service_distributions=[ciw.dists.Lognormal(*get_lognormal_vars(1.0/throughput, sigma* 1.0/throughput))],
number_of_servers=[server_count]
)
Q = ciw.Simulation(N)
Q.simulate_until_max_customers(10**6, progress_bar=True)
servicetimes = [r.waiting_time + r.service_time for r in Q.get_all_records()]
return (server_count, np.percentile(servicetimes, 50), np.percentile(servicetimes, 99), np.percentile(servicetimes, 99.9))
>>> server_count, p50_latency, p99_latency, p99.9_latency = get_service_time(2 * 100000, 1.0, 100, 0.2)
>>> print(server_count, p50_latency, p99_latency, p99.9_latency)
(20, 0.24202101961395783, 0.47748099008185135, 0.49158595663888643)
Yikes! 490ms is quite a bit far away from the 20ms that we are targeting. We
could add more servers to improve the performance. But how many do we add? Let’s
do a sensitivity analysis of how the 99.9th percentile service time
changes with increased servers.
| Server count | P99.9 Latency (ms) |
|---|---|
| 20 | 658.552149 |
| 21 | 40.867156 |
| 22 | 25.780134 |
| 23 | 22.037392 |
| 24 | 19.995492 |
| 25 | 18.984054 |
| 26 | 18.523606 |
| 27 | 18.390090 |
| 28 | 18.239713 |
There is a clear knee in the graph at 24 servers where the P99.9 latency drops
below our target of 20ms. Cool, that means we provision 20% additional
machines, or in other words, run the servers at an utilization of 83.3%.
Attempt #4
Dagnabbit! The data center is in the path of a hurricane. Oh, how ye pain me. The customers are not going to be happy with downtime. Actually come to think of it, maybe I just got lucky until now. Either of the datacenters could have become unavailable for any number of reasons - network outages, acts of god, physical infrastructure failure, and what not.
I know what I will do, I will spread the server across two different datacenters - so 12 in DC1 and 12 in DC2. Hmmm, but what happens if the hurricane hits? We will need to shutdown DC1, so the service will need to run on just 12 servers. We know that makes people unhappy. I need to do “N+1” redundancy. Since I have two datacenters, I need 24 servers each. But that doubles the number of servers again.
Attempt #5
Just as things were getting a bit quiet, the customer complaints are back. What is it now? Oh humbug, the original problem requirements are no longer correct. Turns out the customers like the application, and more and more customers are signing up.
I suppose historical usage is representative of future growth. We appear to be
growing at about 10% quarter on quarter. I will need to make sure to provision additional
machines at regular intervals now. And I still need to make sure they are
positioned properly to have the redundancy we need. This means that by next
year, we will need (1 + 0.1)^4 * 24 * 2 ~= 71 servers.
[In a real setting, we would do this more rigorously. But you get the idea.]
Attempt #6
I am beginning to think that my primary job is to listen to complaints. Now that the customers are happy with the performance, the finance team is unhappy. The service costs way too much to run. Let’s see what I can do.
Hey, I have an idea. The N+1 redundancy buffer is equal to the size of the largest failure domain. If I could increase the number of failure domains, the buffer should reduce. But hmm, we only have a presence in 3 datacenters, and DC3 only has enough resources to run 10 servers. For N+1 redundancy I would need to have a redundancy buffer equivalent to the size of the largest failure domain. If we size the service as 14 servers in DC1, 14 servers in DC2, and 10 in DC3 we reduced the number of deployed servers from 48 to 38.
Attempt #7
Maybe we could do more to optimize this. We have been focusing on horizontal scaling. Maybe we could also try vertical scaling? If each server is larger, it can handle more requests, but will it be able to scale super-linearly? Presumably, it could upto a certain extent, since the static costs of initilization and such will be amortizes and it will have better in-process cache effects. Let’s do a stress test on different machine sizes and see how the service rate changes.
[Again, this is much more complex in reality but the principle stands - there are a lot more dimensions - do you scale the speed of the processor, number of cores on the processors, hyperthreading support, processor platform, etc]
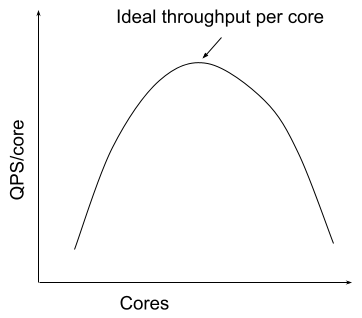
Oh sweet. It looks like if I double the server size, I can triple the
throughput. That means reducing the total processing core demand from 24 cores
to 24 * 2 / 3 ~= 16 cores across 8 servers. Since I have 8 server slots
available in each DC, I can spread the servers equally minimizing the redundancy
buffer - 3 in each. We went from 38 servers down to 9 servers (or 38 CPU
cores to 18 cores).
An astute reader would notice that this was primarily performance modeling rather than capacity planning. That is true, but this is indeed the first step toward capacity planning. In subsequent posts, we will dig into forecasting, risk pooling, and supply chains.